Web開発を学ぶために個人開発しているシステムの構成や実装上の工夫点をまとめます
現在、Web開発の学習のためにショッピングサイトを作成しています。
ゆる〜くコツコツと開発を進めており、気がつけば開発を始めてから約半年が経過していました。それによって、徐々にシステム構成や実装上の工夫点を自分でも覚えておけなくなっているので、ここにまとめておきます。
技術スタックとシステム構成
技術スタックは次のようになっています。
| カテゴリ | 技術 |
|---|---|
| フロントエンド | TypeScript, React, Next.js (pages directory), TanStack Query, Mantine, React Hook Form, Zod, Orval |
| バックエンド | Go, Fiber, sqlc |
| データベース | Amazon RDS (PostgreSQL) |
| ストレージ | Amazon S3 |
| デプロイ | Vercel, AWS App Runner, Amazon ECR, Docker |
| CI/CD | GitHub Actions |
| その他 | Storybook, Chromatic, ESLint, Prettier, Jest, React Testing Library, Mock Service Worker, Swagger |
また、システム構成は、次の図のようになっています。

フロントエンドとバックエンドのコードはともに、GitHubにプッシュすると自動的にデプロイされるようになっています。フロントエンドは、VercelとGitHubリポジトリを連携することで、自動的にVercelにデプロイされます。バックエンドは、GitHub Actionsを使ってDockerイメージのビルドとAmazon ECRへのプッシュを行い、その後、AWS App Runnerを使ってデプロイされます。
技術選定の方針
技術選定は、次のようなものを考慮して行いました。
- 学習のために、最近のWeb開発のトレンドを取り入れる
- 採用することで、シンプルな書き方で実装できたり、コードの自動生成などによって少ないコード量で実装ができたりするライブラリを選ぶ
- 開発の負担を少なくすることで、システムの品質も高めやすくなると思っています
- 出来るだけ、最近も活発にメンテナンスされている技術を選ぶ
- 主に、GitHubリポジトリのスター数や最終コミット日時、最近のコミット頻度を確認しています
プログラミング言語
プログラミング言語には、静的型付け言語であるTypeScriptとGoを選択しました。選択した理由としては、業務で動的型付け言語(JavaScript, PHP)を使った大規模なシステム開発を経験する中で、エラーの早期発見が難しいことや、型が明示されていないコードを理解するのに時間がかかることを課題に感じたからです。
フロントエンドのライブラリ選定
フロントエンドに関しては、自前で実装するのが難しい部分を、ライブラリに任せることで開発の負担を減らしました。例えば、次のような部分です。
- フォームの値の管理やバリデーション
- 使用ライブラリ:React Hook Form, Zod
- APIとのやり取りや取得したデータのキャッシュ
- 使用ライブラリ:TanStack Query
- ボタンなどの共通UIコンポーネント
- 使用ライブラリ:Mantine
バックエンドの技術選定
この個人開発を始めるまで、Goの開発経験はありませんでした。また、REST APIの開発自体、業務でもそこまで経験していない時期でした。そのため、優れた教材を探して、その構成をベースにすることにしました。教材探しにはかなりこだわりましたが、最終的には、次の教材を参考にしました(Youtubeに無料で公開されているのですが、ボリュームも多く、かなり良い教材だと思います)。
https://www.youtube.com/playlist?list=PLy_6D98if3ULEtXtNSY_2qN21VCKgoQAE (opens in a new tab)
ただし、教材の中ではWebフレームワークとしてGinを使っていましたが、あえて少し異なる環境にすると開発スキルが身につきやすいと考え、Fiberを使うことにしました(一応、GinとFiberの書き方を見比べて、大きくは変わらなさそうだという確認はあらかじめ行いました)。
ディレクトリ構成
まず、フロントエンドもバックエンドも、1つのリポジトリにソースコードをまとめています。フロントエンドのコードはwebディレクトリに、バックエンドのコードはapiディレクトリにそれぞれ格納しています。
同じリポジトリにまとめた理由は、フロントエンドとバックエンドの開発を同時に進めることができるからです。1人で開発する分には、別々のリポジトリにして分離するよりも、開発効率の観点で良いと考えました。また、後述しますが、Swaggerドキュメントを元に、フロントエンドからAPIに対してリクエストを送るコードを自動生成する仕組みを導入しているので、その点でも同じリポジトリにまとめた方が良いと考えました。
フロントエンドのディレクトリ構成
フロントエンドのディレクトリ構成は、次のようになっています。
apiディレクトリ
Swaggerドキュメントを元に、Orvalというライブラリを使って自動生成された、APIとのやり取りに役立つコードを格納しています。
componentsディレクトリ
全体で共通して使うコンポーネントを格納しています。現在は、React Hook Formの仕組みにMantineのUIを組み合わせたフォームコンポーネントや、Next.jsのImageコンポーネントをラップした画像コンポーネント、ページのレイアウトコンポーネントなどを格納しています。
featuresディレクトリ
システムの機能ごとにディレクトリを分けて、その機能に関するコンポーネントやフックなどを格納しています。例えば、認証に関連するコンポーネントやフックはauthディレクトリ、商品に関連するコンポーネントやフックはproductsディレクトリに格納しています。
hooksディレクトリ
全体で共通して使うフックを格納しています。
pages、page-componentsディレクトリ
pagesは、Next.jsで定義されている、ページコンポーネントを格納するディレクトリです。ただ、pages内にコンポーネントを置くと、Next.jsによって自動的にルーティングが設定されてしまい、コンポーネント分割などの自由度が低いです。そこで、ページの実態はpage-componentsディレクトリに置き、pagesディレクトリは、それらのコンポーネントをラップするだけにしています。これにより、pagesディレクトリは、ルーティングの責務だけを持つようにしています。
providersディレクトリ
全体で共通して使うプロバイダを格納しています。
test-utilsディレクトリ
テストコードを実装するときに使うユーティリティ関数を格納しています。
typesディレクトリ
全体で共通して使う型を格納しています。
utilsディレクトリ
全体で共通して使うユーティリティ関数を格納しています。
バックエンドのディレクトリ構成
- main.go
apiディレクトリ
APIに関するコードを格納しています。具体的には、サーバの起動処理や各エンドポイントのハンドラ、各ドメインのモデルやサービスを格納しています。
dbディレクトリ
sqlcによるDB操作のためのコードを格納しています。
docsディレクトリ
swagというライブラリによって自動生成されるSwaggerドキュメントを格納しています。
scriptsディレクトリ
スクリプトを格納しています。現在は、DBに動作確認用の初期データを投入するスクリプトを格納しています。
test_utilディレクトリ
テストコードを実装するときに使うユーティリティ関数を格納しています。現在は、テストコード実行時に使用するDBをセットアップする関数などを格納しています。
tokenディレクトリ
セッション管理に使うトークンを生成する関数を格納しています。
utilディレクトリ
全体で共通して使うユーティリティ関数を格納しています。
main.go
サーバの起動処理を記述したエンドポイントとなるファイルです。
実装上の工夫点
API仕様に関するコードの自動生成
バックエンド側では、swagというライブラリを使って、次のような情報からSwaggerドキュメントを自動生成しています。
- APIのリクエストやレスポンスを表す構造体
- ハンドラの仕様を記述したコメント(ハンドラ関数の上に記述しています)
自動生成に使用するコードの一部を次に示します。
package user_domain
type LoginRequest struct {
Email string `json:"email" validate:"required,email" swaggertype:"string"`
Password string `json:"password" validate:"required,min=8"`
}package api
// @Summary Login
// @Tags Users
// @Param body body user_domain.LoginRequest true "User object"
// @Success 200 {object} messageResponse
// @Failure 400 {object} errorResponse
// @Failure 401 {object} errorResponse
// @Failure 500 {object} errorResponse
// @Router /users/login [post]
func (h *userHandler) login(c *fiber.Ctx) error {
// ...
}また、フロントエンド側では、Swaggerドキュメントを元に、Orvalというライブラリを使ってAPIとのやり取りに役立つコードを自動生成しています。具体的には、次のようなコードを生成しています。
- APIのリクエストやレスポンスの型定義
- APIとのやり取りを行うフック
自動生成されたコードの一部を次に示します。
export interface UserDomainLoginRequest {
email: string
password: string
}import type { UseMutationOptions } from '@tanstack/react-query'
import { useMutation } from '@tanstack/react-query'
import type { ErrorType } from '../../custom-axios-instance'
import { customAxiosInstance } from '../../custom-axios-instance'
import type { ApiErrorResponse, UserDomainLoginRequest } from '../../model'
export const usePostUsersLogin = <
TError = ErrorType<ApiErrorResponse>,
TContext = unknown
>(options?: {
mutation?: UseMutationOptions<
Awaited<ReturnType<typeof postUsersLogin>>,
TError,
{ data: UserDomainLoginRequest },
TContext
>
request?: SecondParameter<typeof customAxiosInstance>
}) => {
const mutationOptions = getPostUsersLoginMutationOptions(options)
return useMutation(mutationOptions)
}これらのコードからも分かるように、生成されたフックは内部でTanStack Queryが使われており、これがOrvalを使うことにした理由の1つです(個人的に、TanStack Queryは使いやすく、コードもシンプルに保てるライブラリだと思い、好んで使っていました)。
まとめると、バックエンド側に記述したAPIのリクエストやレスポンス、ハンドラの仕様から、フロントエンド側でAPIとのやり取りに役立つコードの自動生成までを行うことができます。これにより、API仕様の変更にフロントエンド側が追従できる仕組みとなっています。
ログアウト時にAPIから取得したデータのキャッシュを削除する処理
APIから取得したデータは、TanStack Queryによって自動的にキャッシュされています。しかし、セキュリティの観点で、ログアウト時にはセキュアなデータのキャッシュ(ユーザが出品した商品の情報など)を削除する必要があります。ただ、中にはセキュアではないデータのキャッシュ(トップページの商品一覧情報など)もあるのですが、それらは削除しないようにしておきたいです。
キャッシュごとに削除するかどうかを管理するのは、単純に面倒だという問題もありますが、設定を間違えるとセキュアなデータがキャッシュされたままになってしまうというリスクもあります。
そこで、キャッシュを削除する仕組みを次のようにしました。
- 認証を必要としないキャッシュのキーに
non-credentialsを付与する - ログアウト時に、
queryClient.removeQueriesを使って、non-credentialsを含まないキャッシュを削除する
この仕組みを実現するコードを次に示します。
import { QueryKey } from '@tanstack/react-query'
const QUERY_KEY_NON_CREDENTIALS = 'non-credentials'
export function addNonCredentialsToQueryKey(queryKey: QueryKey): QueryKey {
return [QUERY_KEY_NON_CREDENTIALS, ...queryKey]
}
export function isNonCredentialsQueryKey(queryKey: QueryKey) {
return queryKey[0] === QUERY_KEY_NON_CREDENTIALS
}
// セキュアではないデータを取得するフック
export function useGetProducts({
page,
pageSize,
categoryId,
}: UseGetProductsParams) {
const params = {
page_id: page,
page_size: pageSize,
category_id: categoryId,
}
const originalQueryKey = getGetProductsQueryKey(params)
return useGetProductsQuery<GetProductsResultData>(params, {
query: {
queryKey: addNonCredentialsToQueryKey(originalQueryKey),
select: transform,
},
})
}export function useAuth(props?: UseAuthProps): UseAuthResult {
// ...
const logout = useCallback(async () => {
logoutMutation.mutate()
queryClient.removeQueries({
predicate: (query) => !isNonCredentialsQueryKey(query.queryKey),
})
}, [logoutMutation, queryClient])
// ...
}このような仕組みにすることで、基本的にはすべてのキャッシュが削除され、残したいキャッシュに対して明示的にnon-credentialsを付与することになるので、セキュアなデータのキャッシュを削除し忘れる問題が発生しづらくなっていると思います。
フロントエンドのfeaturesディレクトリ
フロントエンドのディレクトリ構成の中に、featuresディレクトリを作っています。このディレクトリは、アプリケーションの機能ごとにディレクトリを分けて、その機能に関するコンポーネントやフックなどを格納するためのディレクトリです。このアイデアは、Bulletproof React (opens in a new tab)というReactアプリケーション向けのアーキテクチャを参考にしました。
featuresの中身の紹介
現在のfeaturesディレクトリの中身を簡単に紹介すると、次のようになっています。
- AuthGuard.tsx
- useAuth.tsx
- useCurrentUser.tsx
- getCurrentUser.ts
- index.ts
- ProductCard.tsx
- ProductCardSkeleton.tsx
- ProductForm.tsx
- ProductList.tsx
- useAddProduct.tsx
- useGetMyProducts.tsx
- useGetProduct.tsx
- useGetProductCategories.tsx
- useGetProducts.tsx
- useUpdateProduct.tsx
- index.ts
- index.ts
- s3.ts
- index.ts
簡単に各ディレクトリや、その中に格納されているものを紹介します(ここで紹介していないものもありますが、長くなるので省略します)。
authディレクトリには、認証に関するものを格納しています。例えば、次のようなものがあります。
- 認証を必要とするページにログインしていないユーザがアクセスしたときに、ログインページにリダイレクトする
AuthGuardコンポーネント - ログインやログアウト、アカウント作成などの処理を行う関数を提供する
useAuthフック - ログインしているユーザの情報を取得する
useCurrentUserフック
productsディレクトリには、商品に関するものを格納しています。例えば、次のようなものがあります。
- 商品の一覧を表示する
ProductListコンポーネント - 商品を出品するときに入力するフォームを表示する
ProductFormコンポーネント - 商品の追加・取得・更新を行うフック群
uploadディレクトリには、画像のアップロードに関するものを格納しています。例えば、次のようなものがあります。
- ファイルをS3にアップロードする関数
featuresディレクトリを採用した理由
理由としては、次の2つがあります。
- 新しいファイルをどこに置くか考えるときに、機能によるカテゴリ分けが直感的に分かりやすいと感じたから
- 1つの機能に関するコンポーネントやフックの距離が近いほうが、構造の理解やファイル管理がしやすいと感じたから
このような理由から採用したのですが、実際に使ってみても考えやすい(脳への負担が少ない)構造だと感じました。
Storybookによる共通コンポーネントの管理
このプロジェクトには、フォームコンポーネントや画像コンポーネントなど、汎用的な共通コンポーネントがあります。また、featuresディレクトリ内にも、機能ごとに共通のコンポーネントがあります。これらのコンポーネントは、Storybookを使って管理しています。
Storybookを導入した一番の理由としては、企業のチーム開発で導入されている事例を見て、勉強しておきたいと思ったからです。本音を言うと、個人開発でも必要かどうかはあまり分かっていないのですが、勉強のために導入しています。
ただ、Storybookは、プロパティとして渡す値を変えることでコンポーネントの表示がどのように変わるのかを確認するプラットフォームとしてとても便利だと感じています。
共通コンポーネントは、様々なケースに対応するために、多くのプロパティを受け取れるようにすることがよくあると思います。ただし、その共通コンポーネントを使う側の視点からすると、どのような使い方ができるのかを網羅的に把握するのは難しいと思います。これは、個人で時間をかけて開発している場合でも同様だと思います。
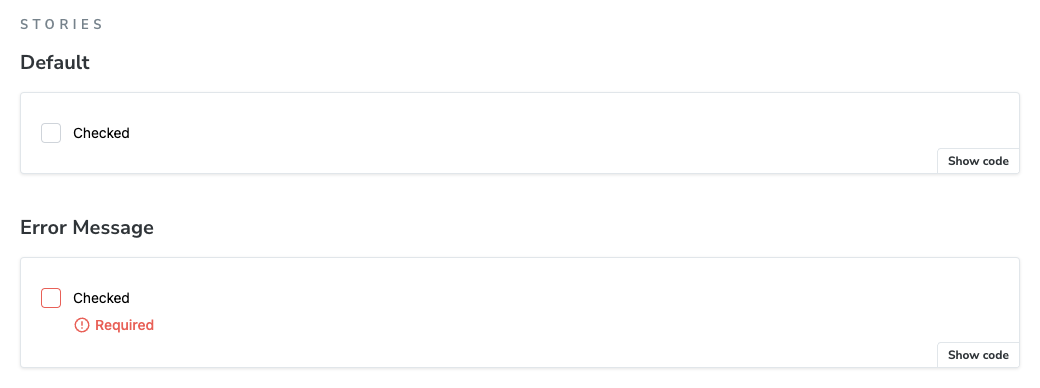
Storybookを使うと、共通コンポーネントの実装者が表示パターンごとにストーリーを作成しておくことで、どのような使い方ができるのかをドキュメントとして残すことができます。例えば、このプロジェクトではCheckboxコンポーネントの通常時・エラー発生時のストーリーを作成しています(以下の画像を参照)。こうしておくと、Storybook上でこれらの表示パターンを並べて確認できるので、使い方を網羅的に把握するのが簡単になります。